




























OneStream Architecture: Monolithic Cube Simplicity or Extensible Multi-Cube Discipline?

Key Points
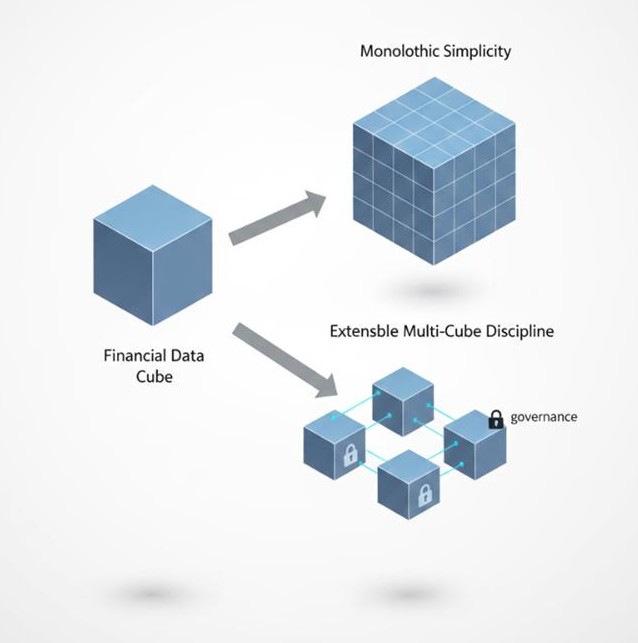
“OneStream Architecture is not about how many cubes you build — it’s about how intentionally you design data units, extensibility, and aggregation boundaries to support consolidation, planning, and analysis without collapsing performance.”
I take a firm position: most architectural failures in OneStream are not functional gaps — they are cube design decisions made without understanding data unit size, extensibility, and dynamic behavior trade-offs. The architecture decision between monolithic, linked, exclusive, hybrid, or dynamic cubes directly determines whether close cycles accelerate or degrade over time.
Below is how I approach it — and why.
A Single Monolithic Cube Is Operationally Elegant — Until It Isn’t
The single-cube design is appealing. One workflow structure. One consolidation path. One set of dimensions. Clean governance.
In statutory consolidation scenarios with controlled dimensionality and predictable data unit sizes (~250k records at upper bound), this works extremely well. Consolidations complete in minutes, cube views render predictably, and calculation status remains manageable.
But the tension appears when:
- Product, project, SKU, or employee-level analysis creeps in
- Planning introduces large sparse UD dimensions
- Forecast cycles multiply scenario volumes
- Finance wants operational analytics in the same cube
Once data units approach large sparse thresholds (~750k+ records), performance shifts from metadata-driven efficiency to CPU-driven stress.
Consolidation time increases not because OneStream is slow — but because the architecture ignored data unit physics.
My conclusion:
A monolithic cube is excellent for tightly governed statutory consolidation. It becomes fragile when used as an analytics warehouse.
Extensible Dimensionality Solves Governance — Not Performance
Extensible Dimensionality is one of the most powerful features in OneStream architecture. It allows corporate to maintain a standard dimension while business units extend locally for management reporting.
This is critical in real-world environments:
- Corporate COA vs. BU detailed accounts
- Actual vs. Budget extension layers
- Different scenario-specific dimensional assignments
In consolidation and planning use cases, this gives structural flexibility without surrendering governance.
However — extensibility does not reduce data unit size. It controls hierarchy behavior and dimensional inheritance. Performance still depends on:
- Parent calculation execution
- Alternate hierarchies
- Data unit density
- Sparse dimension design
I have seen teams assume extensibility is a scaling mechanism. It isn’t. It is a modeling discipline mechanism.
Use extensibility to protect the model.
Do not rely on it to fix performance.
Large Sparse Designs Demand Architectural Discipline
When transactional dimensions (SKU, Project, Employee) enter the model, standard cube assumptions break.
Sparse dimensions increase:
- Consolidation compute load
- Parent aggregation loops
- Cube view rendering time
- Quick view unpredictability
Placing a UD#Top member in a report forces runtime aggregation across potentially thousands of children. That is not a reporting issue — that is an architectural decision manifesting at query time.
In planning and forecasting environments, especially with rolling forecasts, this becomes exponential.
My architectural rule:
If transactional detail is required for analytics but not required for consolidation logic, isolate it.
Do not let analytical density contaminate consolidation data units.
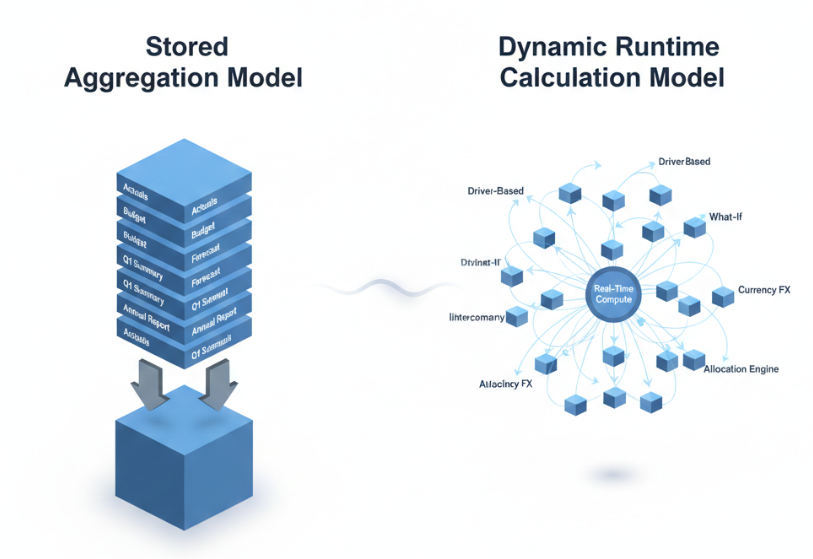
Hybrid Cubes Shift the Trade-Off From Storage to Runtime Logic
Hybrid cube design intentionally avoids storing parent-level aggregation. Parent values are dynamically calculated using API-based entity aggregation.
This is ideal when:
- Base-level calculations are complex
- Parent entities only need simple aggregation
- The cube is analytics-heavy, not consolidation-heavy
In forecasting and scenario modeling use cases, hybrid designs can dramatically reduce storage footprint.
But here is the trade-off:
- Parent data cannot be consolidated traditionally
- Exporting aggregated data may require replication logic
- Runtime performance becomes dependent on dynamic rule execution
You are exchanging stored stability for runtime flexibility.
For analytics-driven FP&A environments, I favor hybrid.
For statutory close, I do not.
Dynamic Cubes Are Not a Shortcut — They Are an Architectural Commitment
Dynamic Cube Services allow real-time data surfacing from external systems or other cubes without traditional workflow loading.
This is powerful for:
- Operational analytics
- Driver-based planning
- Risk analysis
- Headcount or specialty cubes
Dynamic dimensions eliminate stored metadata and source members from external systems. Data bindings control share vs. copy behavior. Workspace assemblies manage refresh cadence.
But dynamic architecture introduces complexity:
- Timestamp-based refresh logic
- Write-back constraints (Forms origin only)
- Data unit size recommendations still apply
- Dynamic members do not behave like stored dimensions in all scenarios
In consolidation environments, dynamic cubes must be used carefully. They can participate in consolidation sequences — but design mistakes propagate quickly.
Dynamic cubes are not “faster cubes.”
They are purpose-built surfaces for specific data patterns.
The Real Architectural Decision: What Is Your Data Unit Controlling Dimension?
Every OneStream architecture decision ultimately revolves around the data unit:
Cube + Entity + Parent + Consolidation + Scenario + Time 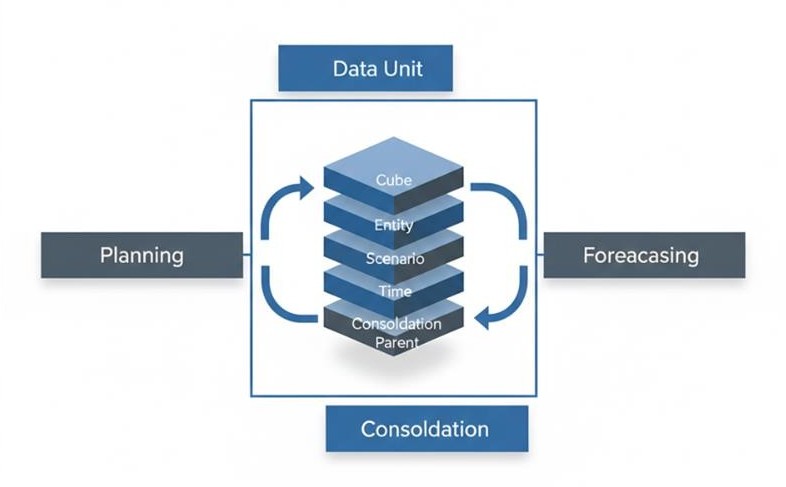
If you misidentify the controlling dimension — typically Entity — you will:
- Inflate consolidation cycles
- Complicate workflow ownership
- Introduce unnecessary intercompany elimination complexity
- Struggle with hybrid scenario integration
Before choosing cube types, I ask:
- Is Legal Entity truly the controlling dimension?
- Does planning require a different controlling axis?
- Are specialty cubes justified?
- Can linked cubes reduce unnecessary consolidation volume?
Architecture is not about cube count.
It is about controlling dimensional explosion.
The Risk Most Teams Ignore
The most common failure pattern I see:
Trying to serve consolidation, operational analytics, driver-based planning, and scenario simulation inside a single architectural model.
Technically possible.
Architecturally unstable.
Over time:
- Business rules multiply
- Parent calculations increase
- Dynamic logic layers stack
- Performance becomes inconsistent
- Governance erodes
The risk is not system failure — it is architectural entropy.
Once entropy sets in, even small enhancements create cascading recalculation effects.
My recommendation for CFOs, FP&A Leaders, and EPM Architects
If you want predictable close cycles, scalable forecasting, and controlled extensibility:
- Keep statutory consolidation clean and disciplined.
- Isolate analytical sparsity into hybrid or dynamic cubes.
- Use extensibility for governance — not performance scaling.
- Respect data unit size thresholds as hard architectural boundaries.
- Treat dynamic architecture as a strategic choice, not a convenience.
Conclusion
OneStream Architecture forces a decision: build for simplicity today or design for controlled scale tomorrow.
I advocate disciplined multi-cube architecture with intentional extensibility and targeted hybrid/dynamic usage.
Not because it is more complex — but because enterprise EPM environments inevitably grow.
And in OneStream, growth punishes architectural shortcuts.
Design the data unit correctly, and consolidation, planning, forecasting, and close will remain predictable.
Design it casually, and performance will become your governance problem.


Rajan Shah
Technical Manager
Rajan Shah is a Technical Manager with OneStream Expertise at Solution Analysts. He brings almost a decade of experience and a genuine passion for software development to his role. He’s a skilled problem solver with a keen eye for detail, his expertise spans in a diverse range of technologies including Ionic, Angular, Node.js, Flutter, and React Native, PHP, and iOS.
